•
우측처럼 쭉 나열되는 구조…..

Building Queries


•
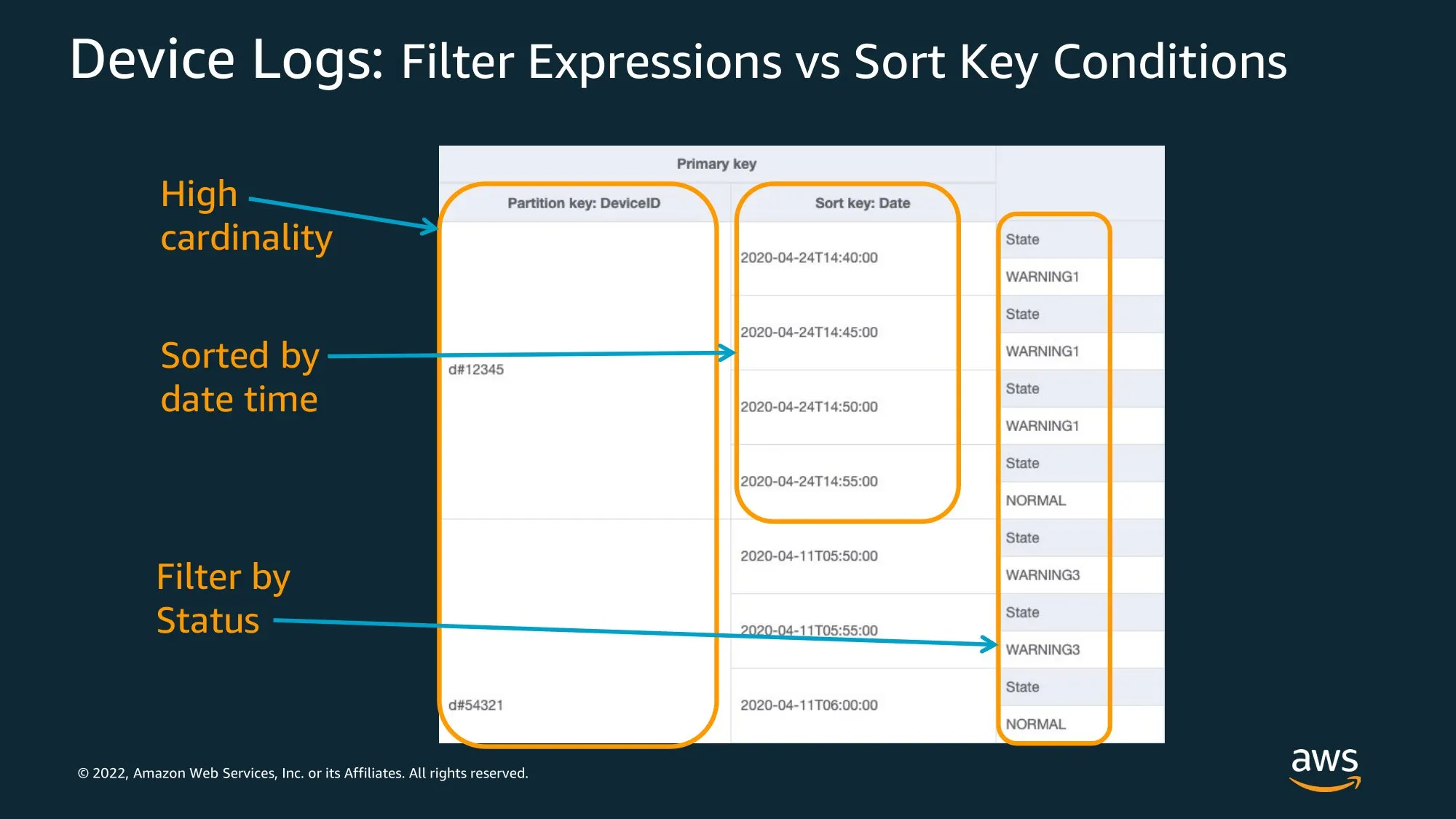
Partition Key로 조회는 equal(=) 인 경우
•
Partition Key : High Cardinality
◦
이 키를 잘못 잡으면 Hot Key가 발생함.
◦
당연히 Access Pattern에서 사용하는 값을 잡아야 함.
•
Sort Key
◦
기본적으로 Partition내에서 Sorting되어있다~
•
Attribute
◦
Filter 조건

•
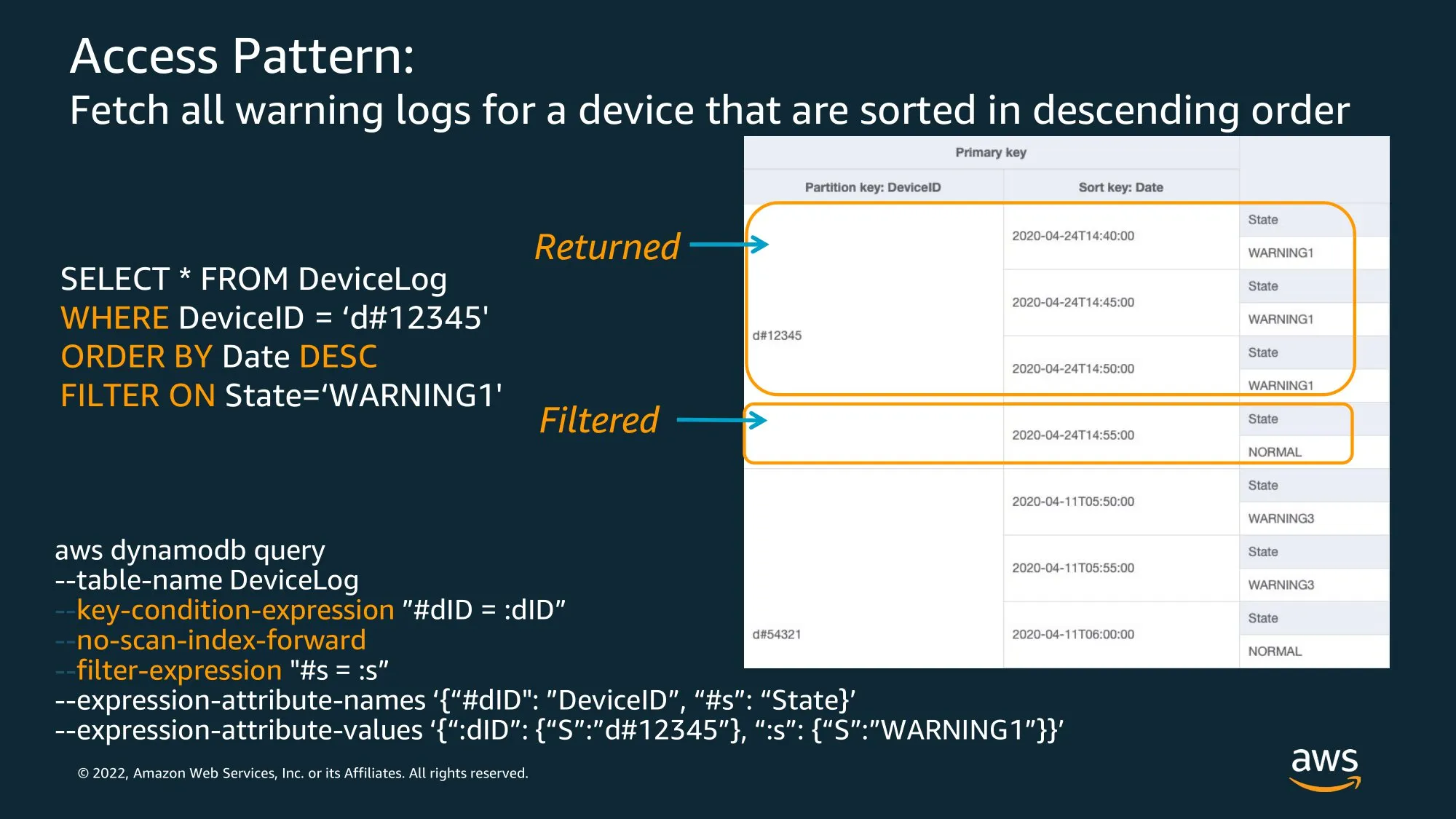
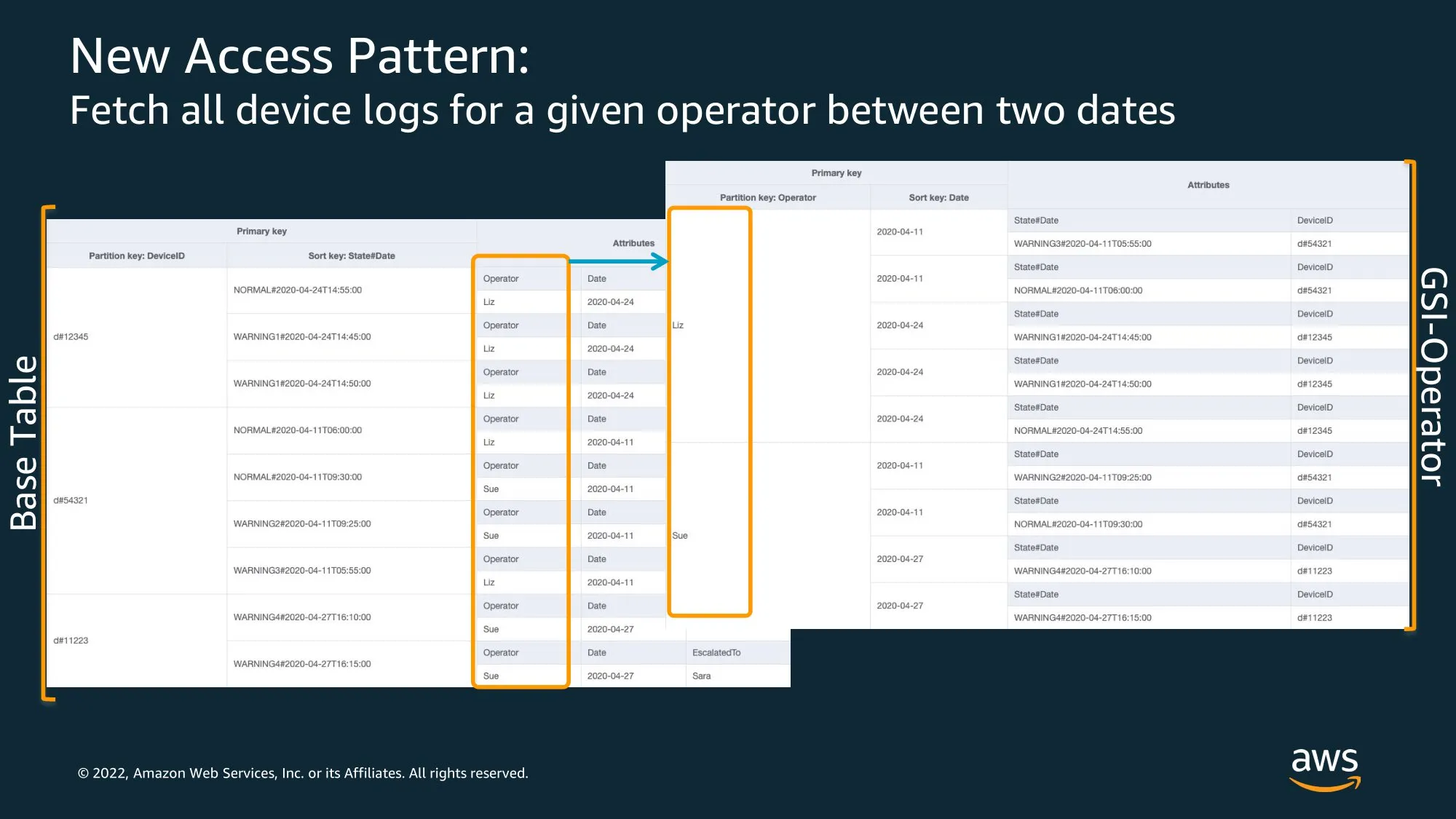
Status 속성을 filter로 처리하지 않고 Query로 처리하기 위해 Sort Key에 Status 속성 포함.
•
‘#’ 기호를 사용해서 조합하는 키를… Composite Sort Key 라고 한다.
•
우측 → GSI 기반


•
GSI를 생성하는 경우 ElascalatedTo 속성 값이 있는 Item만 가지고 생성된다.

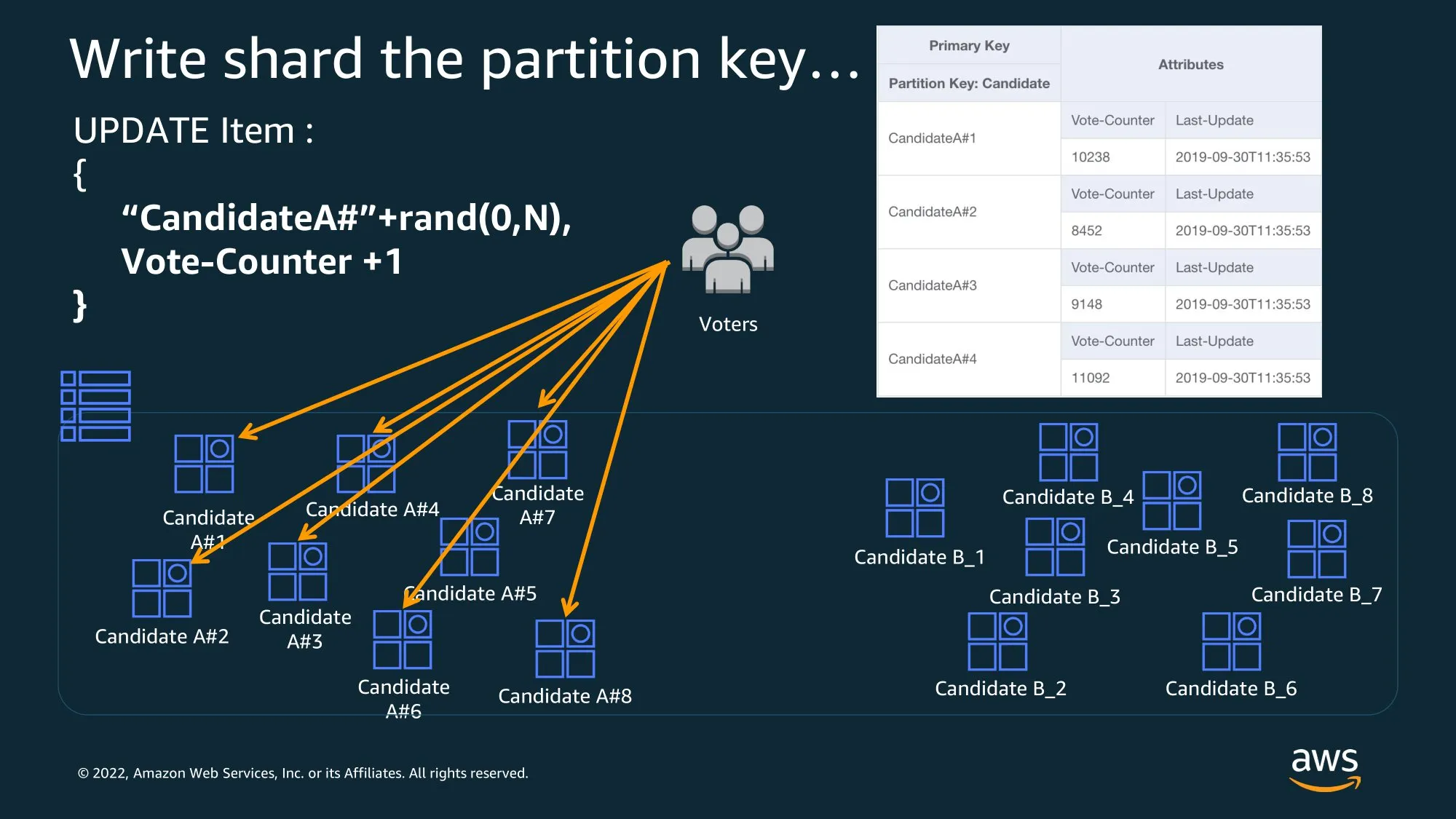
Artificial sharding


•
특정 키를 키+rand(0,N) 값을 붙여서 쪼갠다.

•
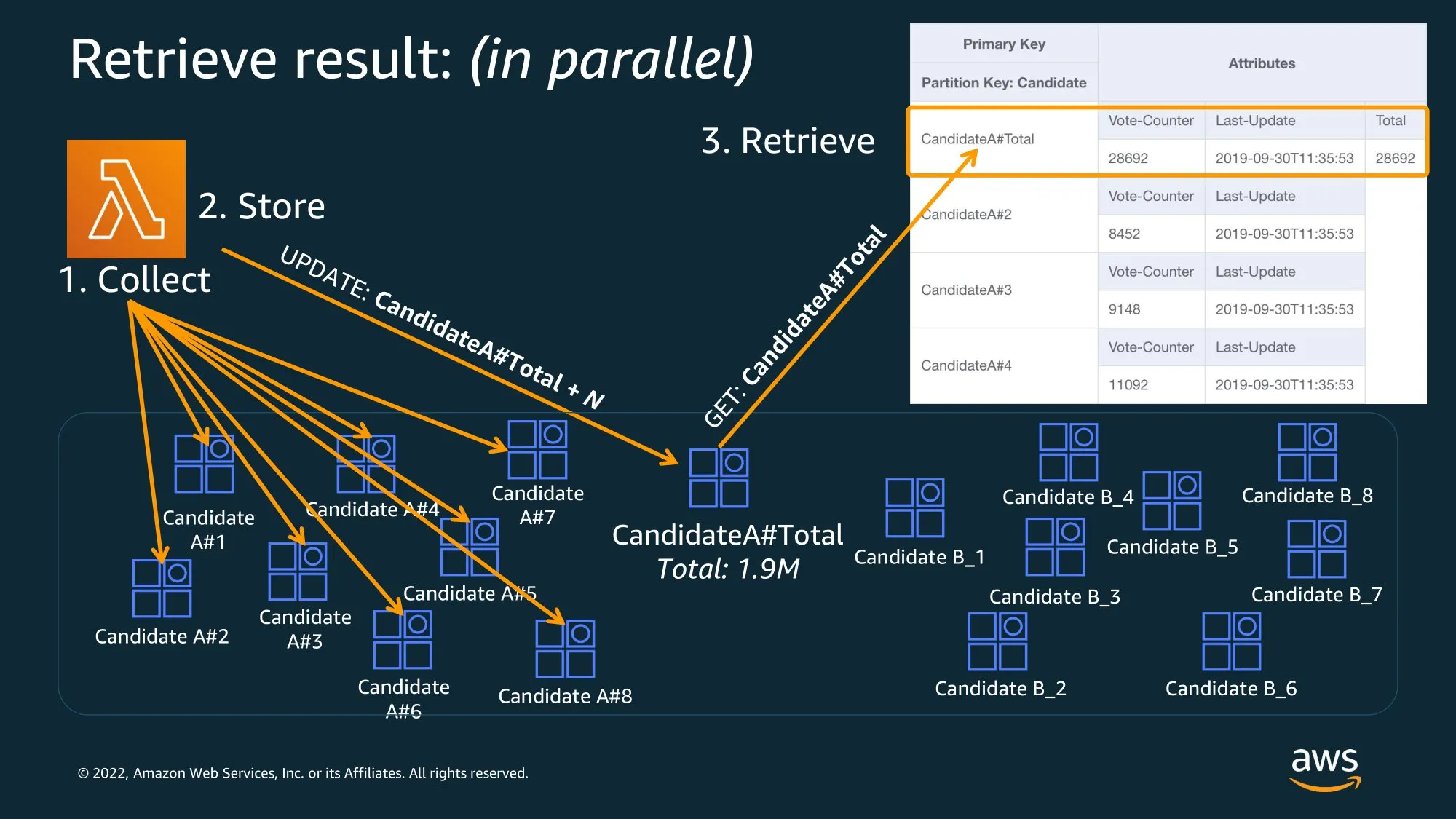
CandidateA#Total 처럼 전체 Partition Key 표를 합친다. +1

Write shard a GSI



Complex Queries & Analytics

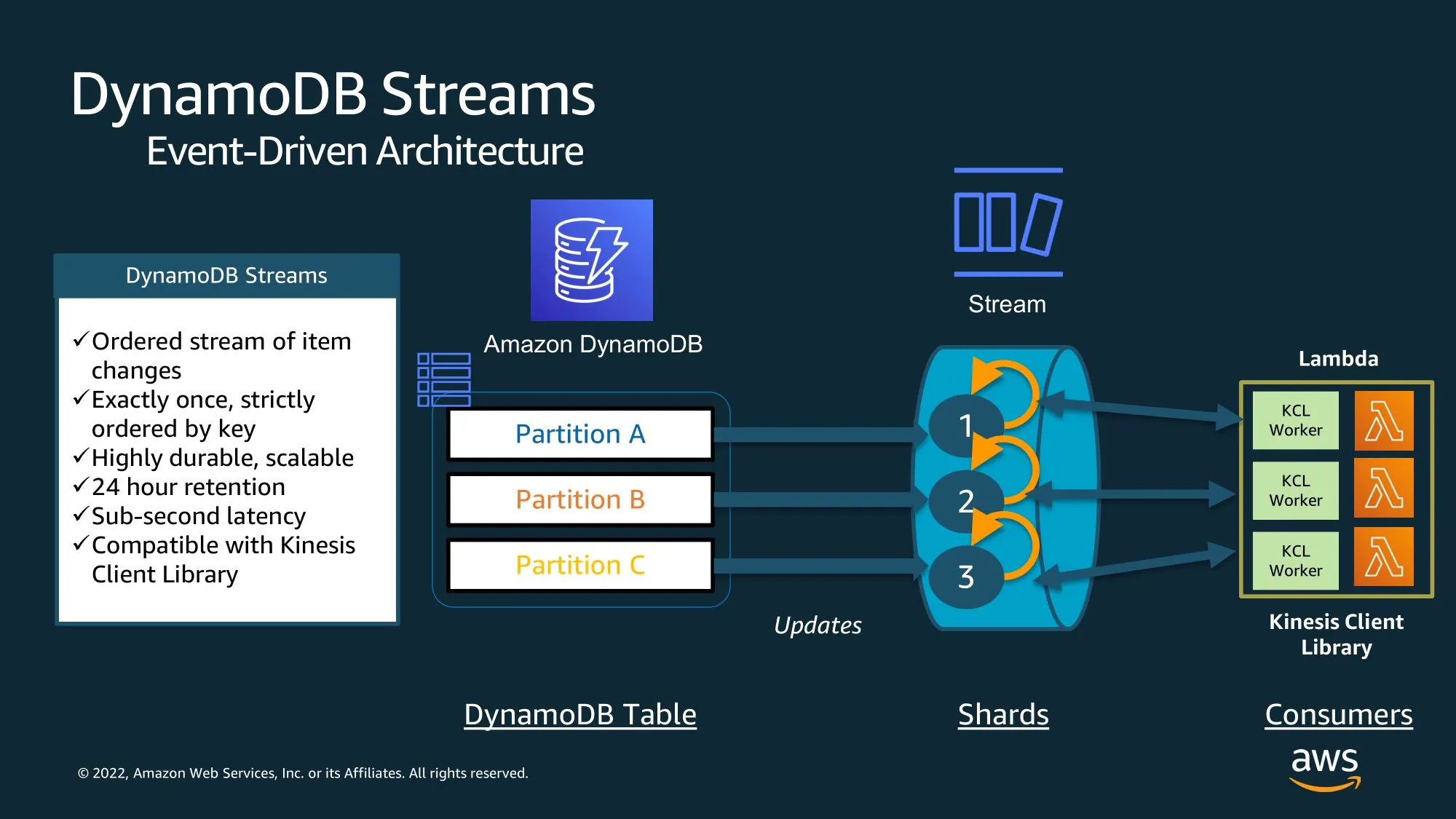
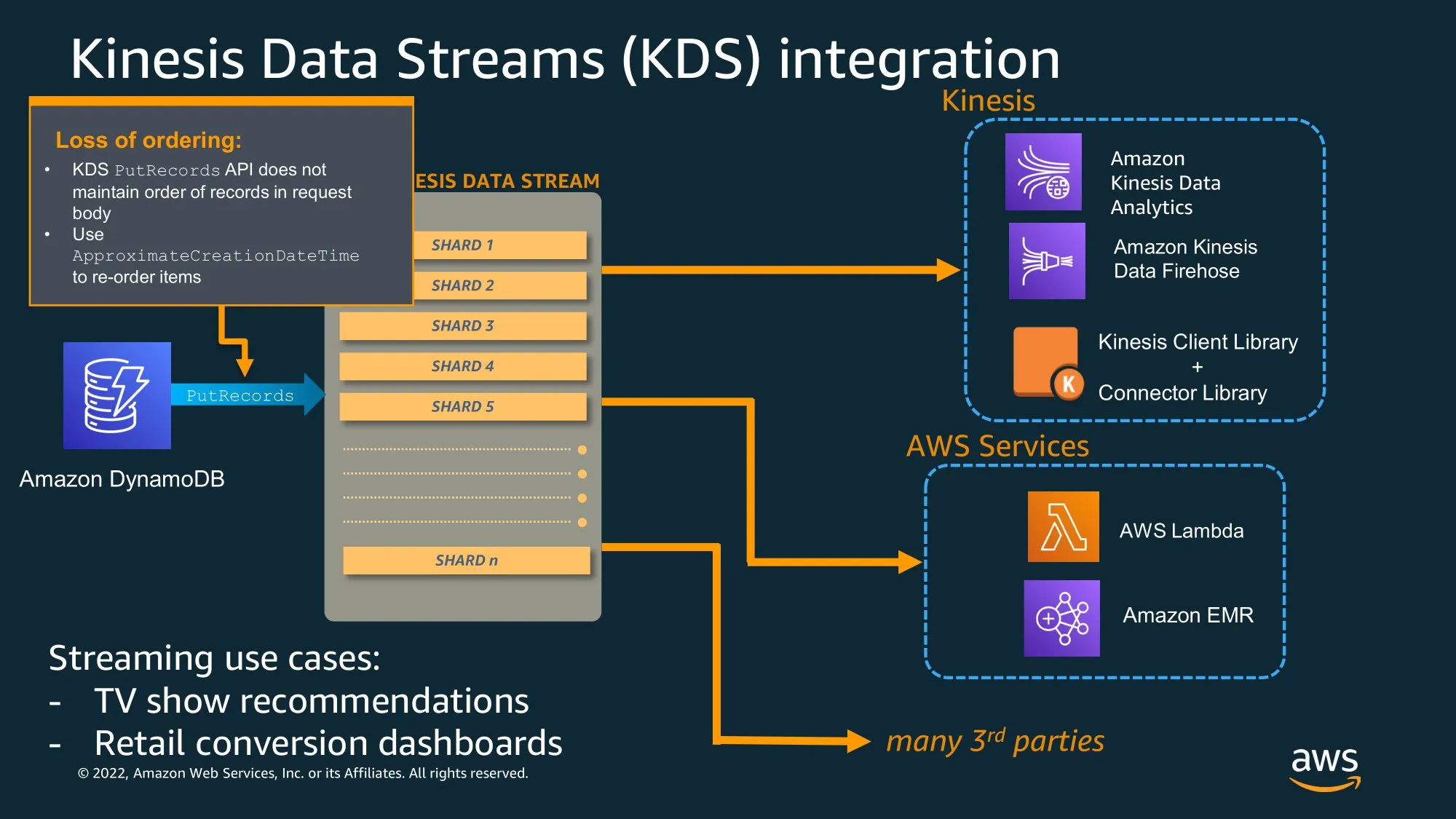
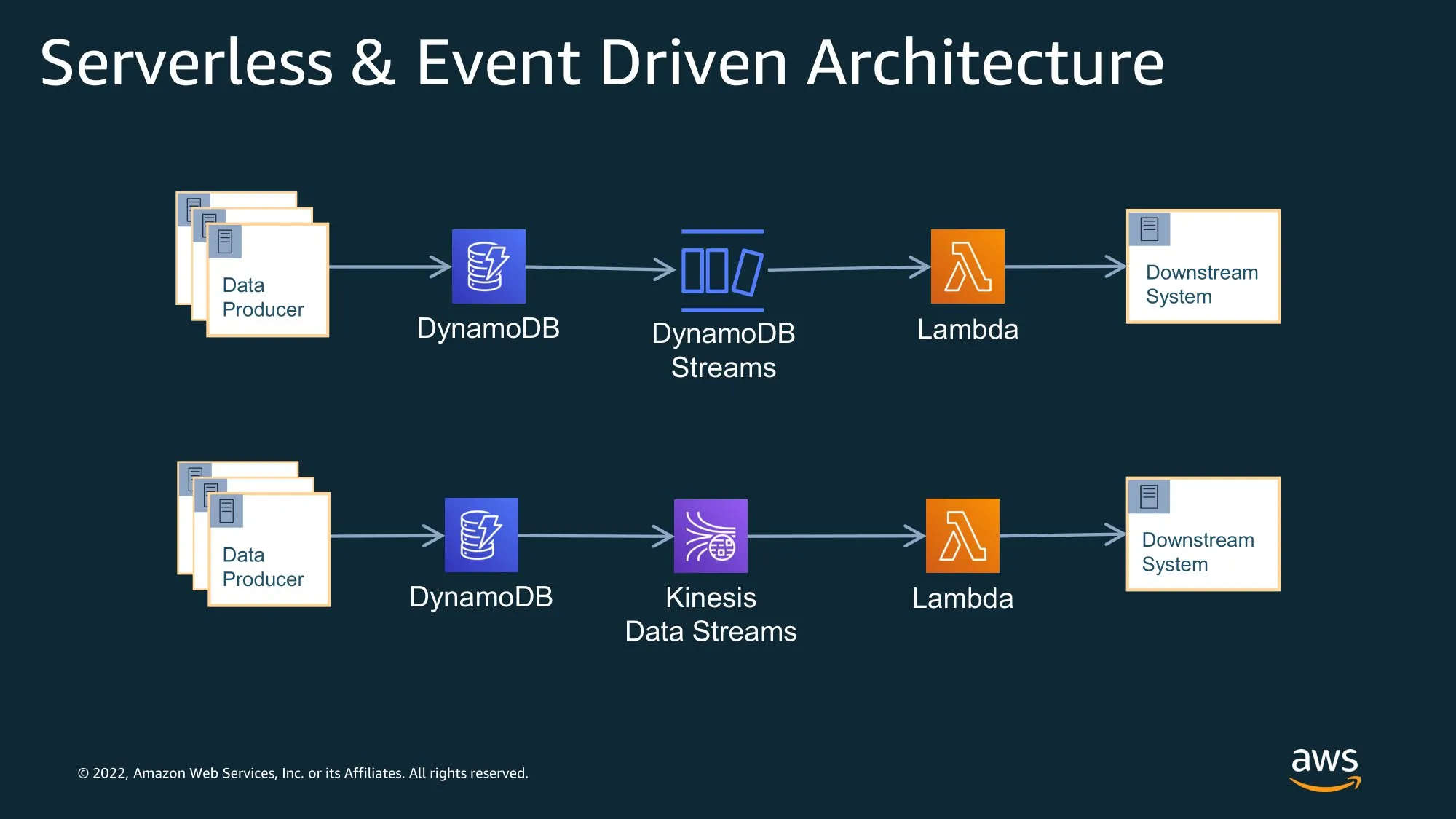
Large Items, Vertical Partitioning, & GSI Overloading


•
Key Name이 값과 같이 저장이 되니 Key Name 길이를 작게 해라! → 비용 절감(Item Size 작아진다)
•
너무 큰 데이터는 S3로… DynamoDB는 메타정보만..

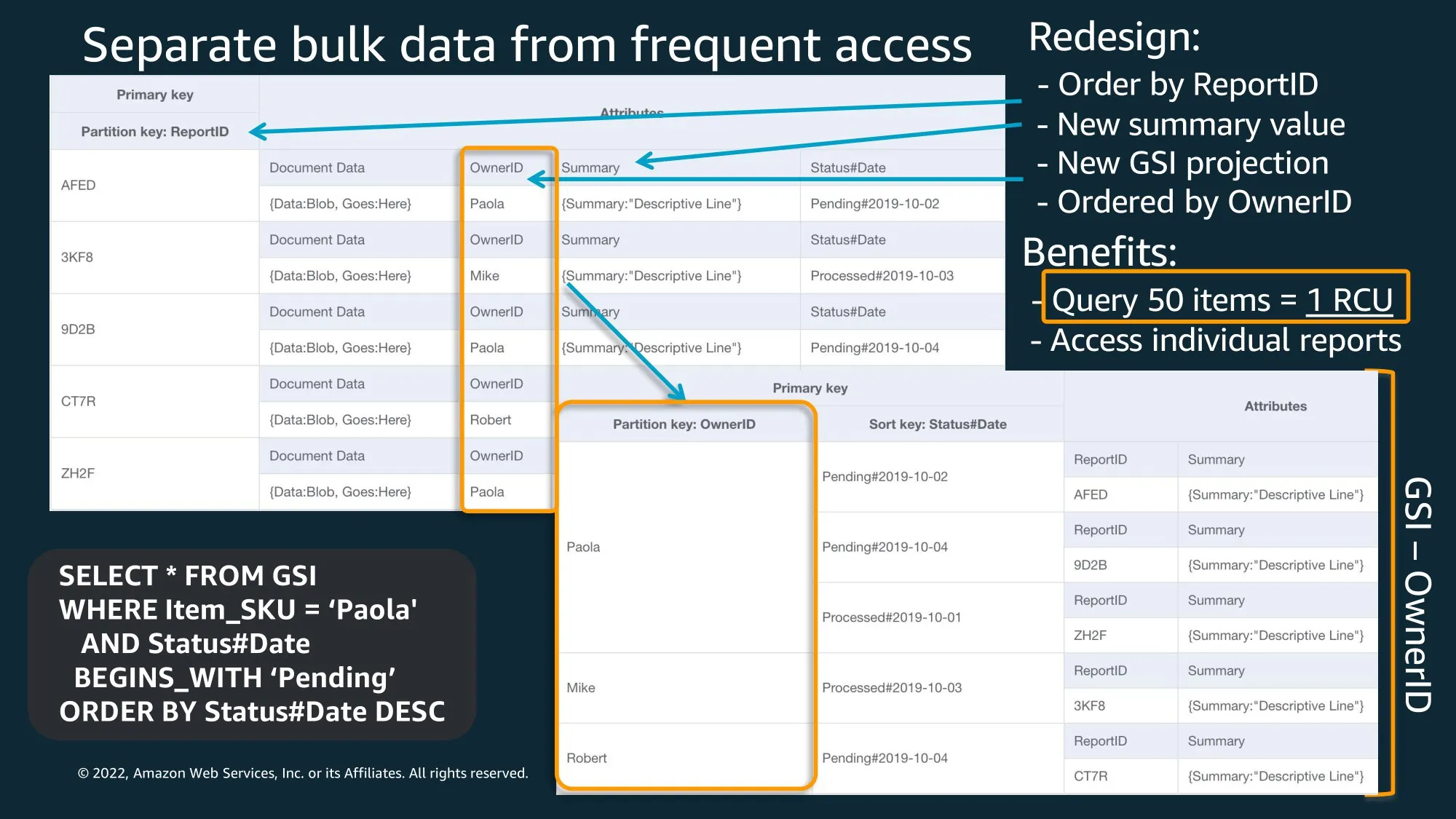
‘Relational’ data modeling


Hierarchical data example

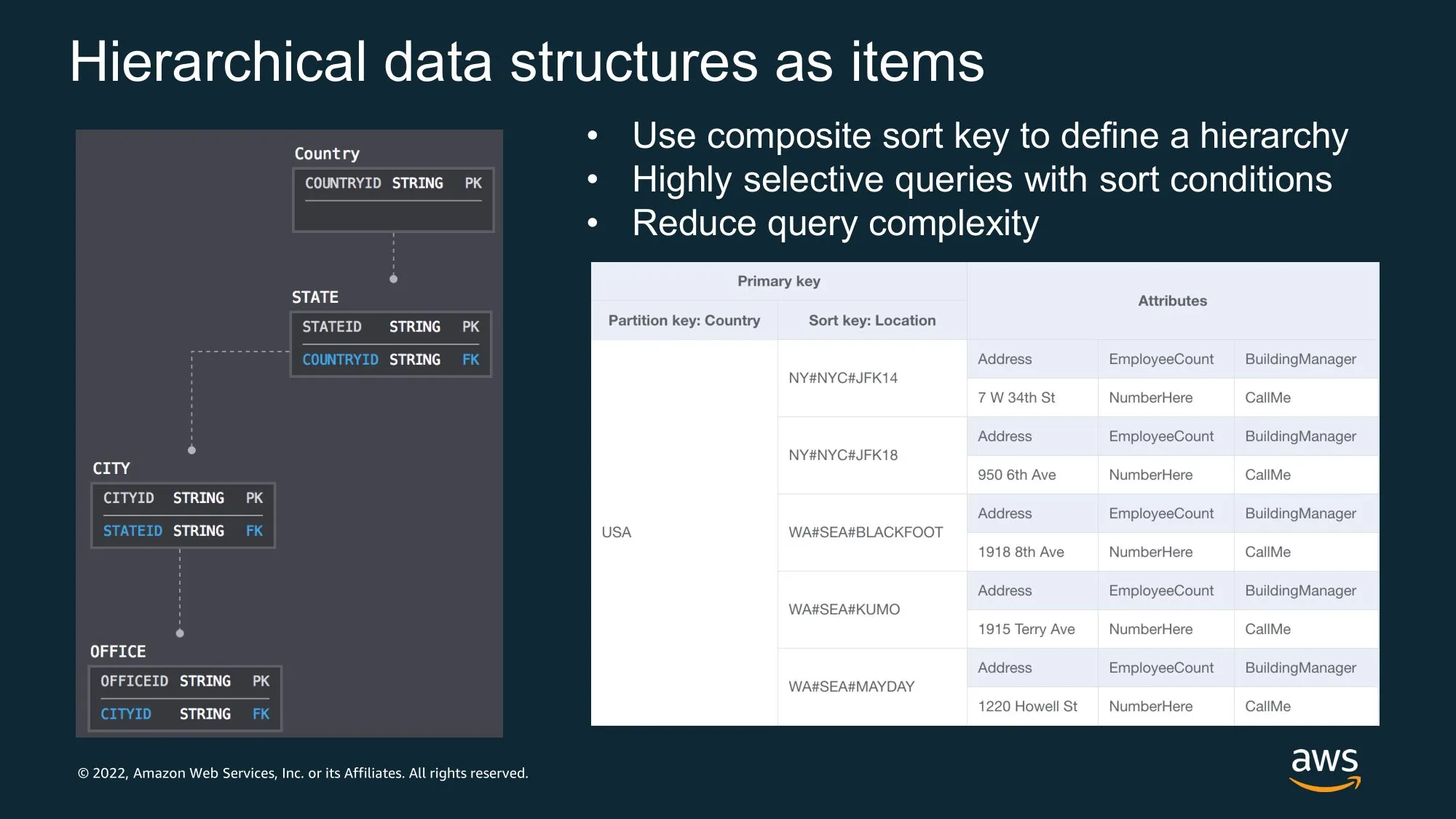

Schema design tools


Hands-on design challenges




What are the access patterns?
The access patterns in the scenario are outlined as:
1.
Insert scheduled payments.
2.
Return scheduled payments by user for the next 90 days.
3.
Return payments across users for specific date by status (SCHEDULED or PENDING).
Identify possible partitions keys to fulfill the primary access pattern:
•
What item attribute (AccountID, ScheduledDate, Status, DataBlob) scales with access patterns?
◦
Partition Key: AccountID
◦
Sort Key: Status#ScheduledDate
•
What is a natural organization for the related payment items (so as to return collected items relative to the access patterns above)?
◦
GSI 생성
▪
Partition Key: ScheduledDate#Status
▪
Sort Key: X
•
Consider the dimension of access: both reads and writes.
When determining how to organize items related to the primary access pattern:
•
What organization do items need to be written with to return items by user for a date range (sort by)?
•
What is the hierarchy of the relationships and when does it apply (most general to more specific)?
Fulfilling the third access patterns:
•
The third access pattern is OLTP and can be fulfilled directly on DynamoDB